版本控制
基本的版本控制,其实就类似于编写文档时的撤销和回退,在需要的时候将当前文本内容变为历史内容。所以程序代码的版本控制系统,核心就在于要保存历史记录,并有一个索引指向代码的各个历史版本,并能够通过索引随时将当前项目的内容替换为历史版本的内容。
VCS和DVCS
常见的版本控制系统,无非就是SVN和Git了,前者是中央式版本控制系统(VCS),后者是分布式版本控制系统(DVCS)。
中央式版本控制系统,大致是这样的:一个项目,所有内容都存放在服务器上的代码仓库中,叫做中央仓库。团队中的每个成员,都可以从服务器获取到一份代码,进行开发。每个人在开发完成后,都需要将自己的新代码提交到服务器上的远程中央仓库中。每当有人提交代码,其他人都可以讲这些更新的代码同步到自己的机器上,来保证项目代码的版本同步。
在分布式版本控制系统下工作流程大致是这样的:一个项目的所有内容存放在服务器上的代码仓库中,即中央仓库。团队中每个成员从服务器获取到一个与远程仓库一模一样的代码仓库,叫做本地仓库。接下来,每个人可以在自己电脑上进行开发,开发完成后的新代码可以直接提交到自己的本地仓库中,和远程仓库完全没有关系,因此这一步也就是离线的。在需要的时候,每个人可以将本地仓库与远程仓库做一次同步,让远程中央仓库保持跟本地仓库一致。每当有人这样提交后,其他成员都可以将自己的本地仓库与远程中央仓库做一次同步,让本地仓库与其保持一致,这一过程是需要联网操作的。
分布式版本控制系统,大体上和中央式是一样的,区别就在于,在中央式版本控制系统中,远程的中央仓库全权负责了历史版本的控制,每个人只能从仓库中获取代码,想仓库上传新代码,仅此而已。而分布式版本控制系统中,每个团队成员从远程中央仓库获取到的不是简单的一份代码,而是一个完整的代码仓库,叫做本地仓库,这个本地仓库保存了整个项目的所有版本信息,就相当于一个远程仓库。
Git
Git就是一种广泛使用的分布式版本控制系统,除了免费的GitHub外,各个公司、团队可以以Git为基础定制化自己的一套系统。Git做版本控制时,他所管理的版本历史记录,不是你代码的记录,而是代码改动的记录。即他不会记下你某个时间点代码内容是什么样的,他记录的是在那个时间点代码有什么样的变动。
常见工作模型
目前常见的Git工作模型大致是这样的:
- 先由主工程师完成基础框架,并将代码推送至服务器上,作为中央仓库
- 中央仓库的代码会有多个分支,比如master,dev等
- 每个成员需要从中央仓库clone一个本地仓库
- 项目的开发工作,基本都是在dev分支做。当完成一个版本的开发后,会合并到master分支
- 每个成员开发时,都需要从dev分支建立属于自己的分支,在这个分支上进行开发
- 成员在开发完成一个小功能时,需要提交代码至自己的本地仓库中
- 在完成一个大模块的开发后,需要将本地仓库同步至远程仓库
- 每个成员在开发过程中药注意保持自己本地仓库与远程仓库同步
提交代码:add 和 commit
在使用Git时,最常见的命令就是 add 和 commit 了。Git中有一个叫做 暂存区(stage) 的东西。每当有新的代码改动,都需要先执行 add 命令将改动加入到暂存区。 add 时,可以指定要加入的内容,比如 add xxx.txt , 也可以偷偷懒一次全部加入 add -A 或 add . 。在加入到暂存区之后,还可以继续开发,也就是可以有多次 add ,每次 add 都会将部分改动加入到暂存区。当你觉得差不多了,可以执行一次 commit ,也就是将当前暂存区内的所有改动,统一标记为一次提交,提交至本地仓库中。在提交后,会自动生成一个字符串,作为这次提交的索引,叫做 commit id 。 而这次提交所生成的 commit ,就相当于一个指针或者引用,指向了这一次提交。
随着工作的进行,会有很多很多 commit 引用,我们只需要知道 commit 对应的id,或者其他手段,获取到这个指针/引用,就可以获取到“在那次提交时项目的代码是怎么样的”。
引用:HEAD 和 branch
前面说 commit 是一种引用,其实Git中除了 commit 之外,还有许多种引用。
首先是 HEAD ,这个引用非常特殊。由于我们有多次提交,也就生成了多个 commit 引用。而 HEAD 引用则指向了当前的 commit 引用,也就是他是指向了引用的引用。当前在哪个 commit 引用上, HEAD 就指向哪里,始终保持在当前。
还有一个引用,叫做 branch 。这个引用可以叫做分支,指向一个 commit ,即他也是指向引用的引用。前面说的 HEAD 除了直接指向 commit 外,也可以指向 branch 引用。 branch 是可以通过执行 git checkout -b xxx 或者 git branch xxx 来任意创建的。在创建一个 branch 之后,可以主动将 HEAD 指向这个引用,之后在开发中,每当有新的提交,新的 branch 将会始终指向新生成的 commit 引用。
系统默认会有一个 branch 引用,名字叫做 master ,这个引用是在创建代码仓库时就创建好的(当然可以自己定制,不过大部分情况默认就叫做master),他是整个项目的主分支,也就是主引用。大多数团队会规定,以 master 为核心,在 master 分支下必须是能对外发布的、功能完整的项目。
一图胜千言,看下如图所示的工作流:
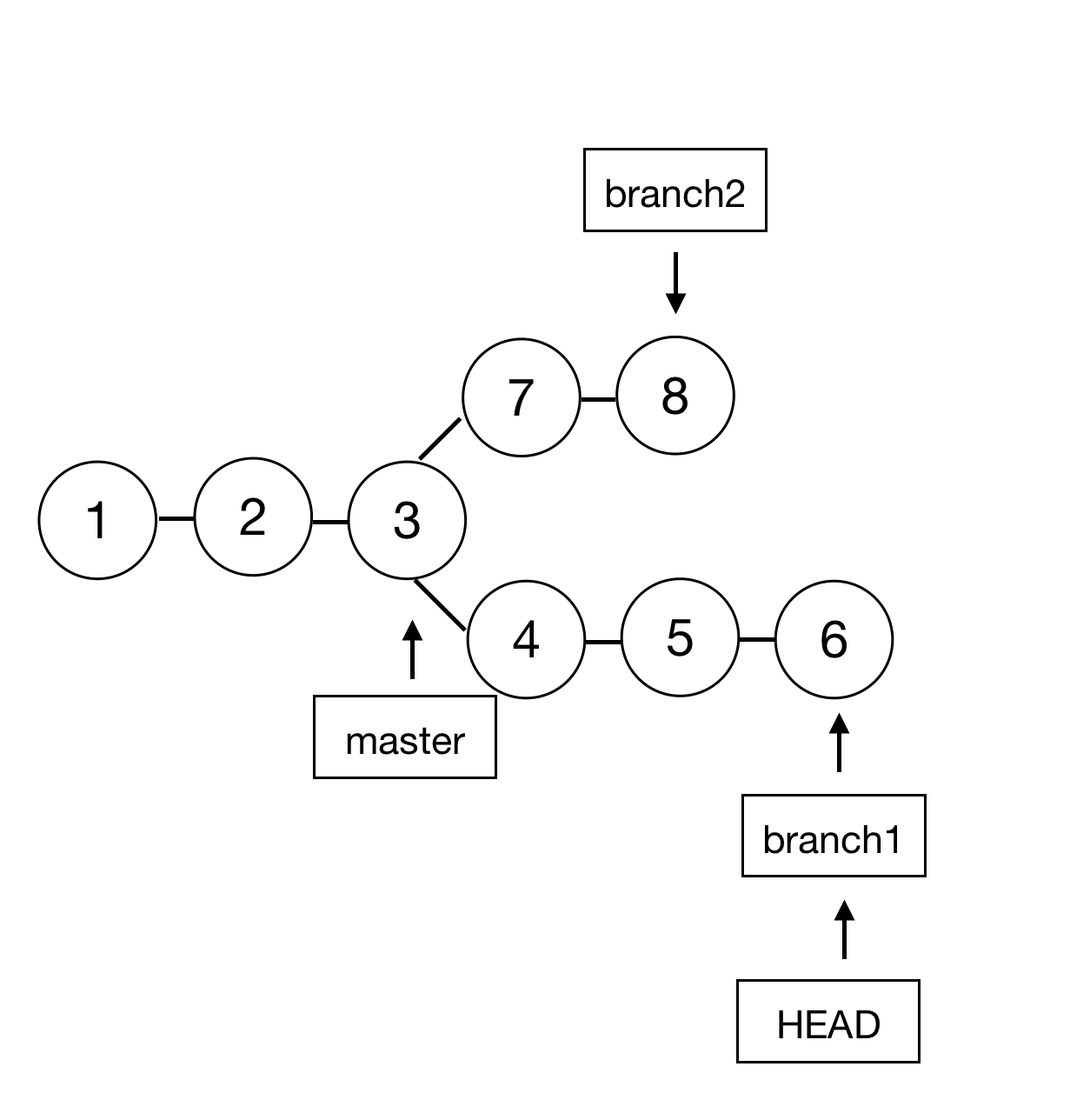
在图中,123456789分别是9个 commit 引用, master 引用指向的3是当前稳定的版本,而 branch1 和 branch2 则分别是两个用来开发新功能的 branch 引用,此时由于 HEAD 引用指在了 branch1 这个引用上,所以当前工作目录下的代码也就是6所对应。
合并代码:merge 和 rebase
为了安全与规范,通常会留一个 master 分支作为一个项目的稳定版本, dev 分支作为一个开发版本,成员基于 dev 分支开发时,要再建一个 feature 分支,并在这个分支进行开发。当然,还有一些更细致的方式,归根结底都是要以分支为单位进行开发。那么在开发完成后,就需要将完成的功能合并到主分支。这里的主分支是相对而言的,可能是小功能的 feature ,可能是 dev ,也可能是 master 。在合并是通常有两种方式, merge 和 rebase 。
第一种 merge ,作用是将两个分支的提交合并在一起,作为一个新的提交。如图所示:
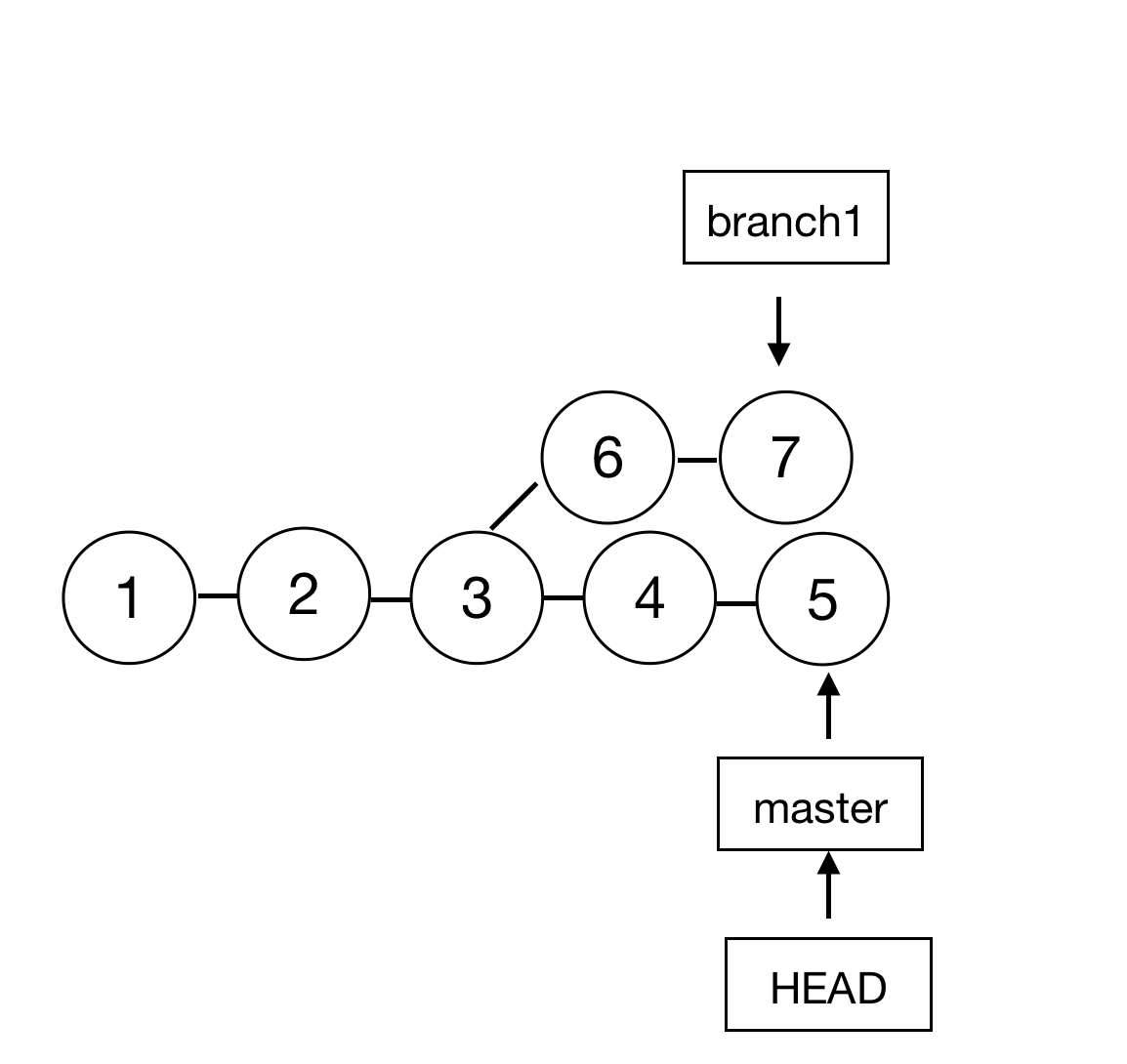
此时 branch1 开发完成,当前工作目录在 master 分支,在这里执行 merge 后的效果:
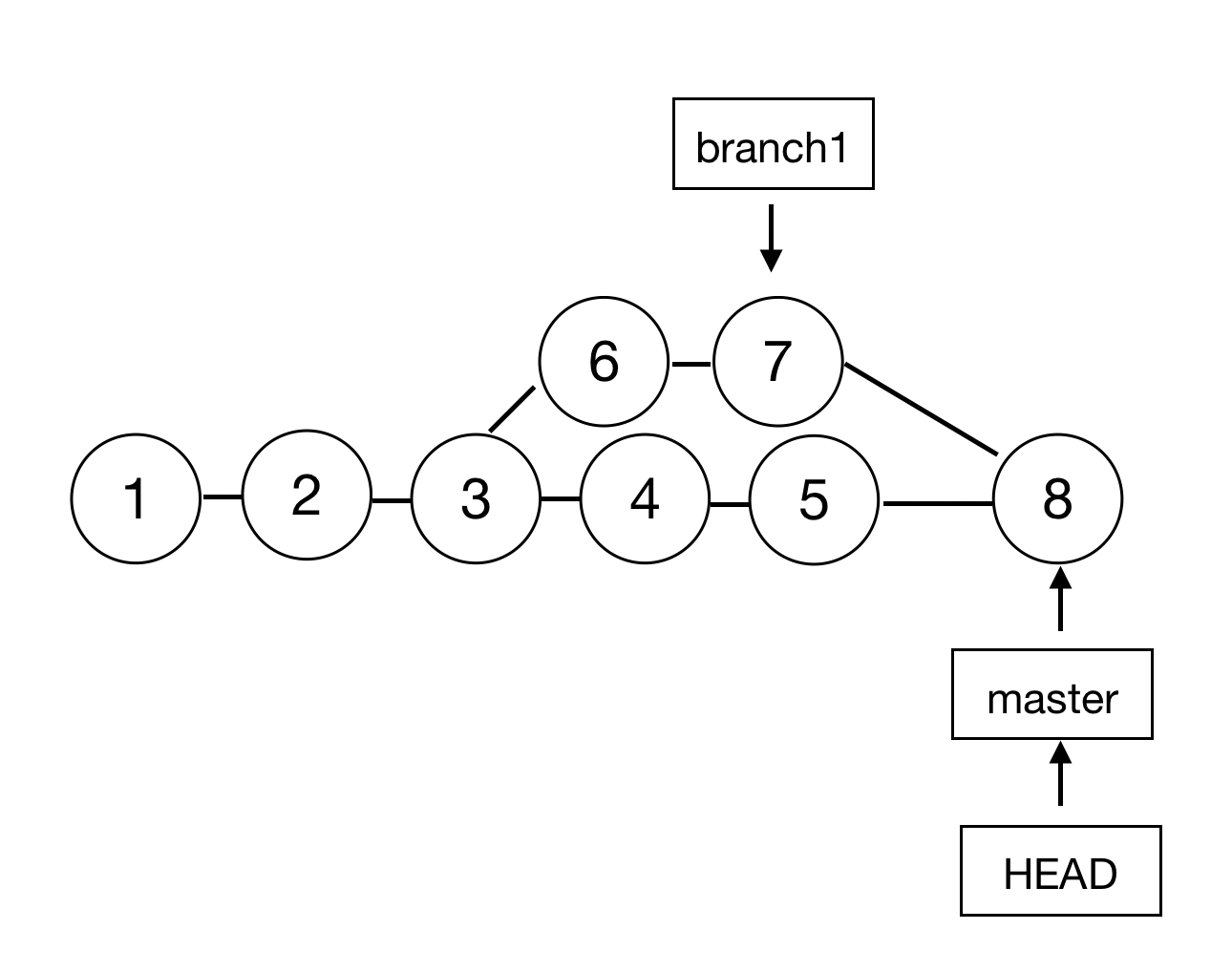
会自动把从分叉点3开始的提交,67和 master 上的提交 45 做合并,并生成一个新的提交8。当然在合并时可能存在冲突,就需要主动解决冲突了。
第二种 rebase ,可以译作变基,也就是将当前一系列提交的基础提交改变为目标分支,如图所示:
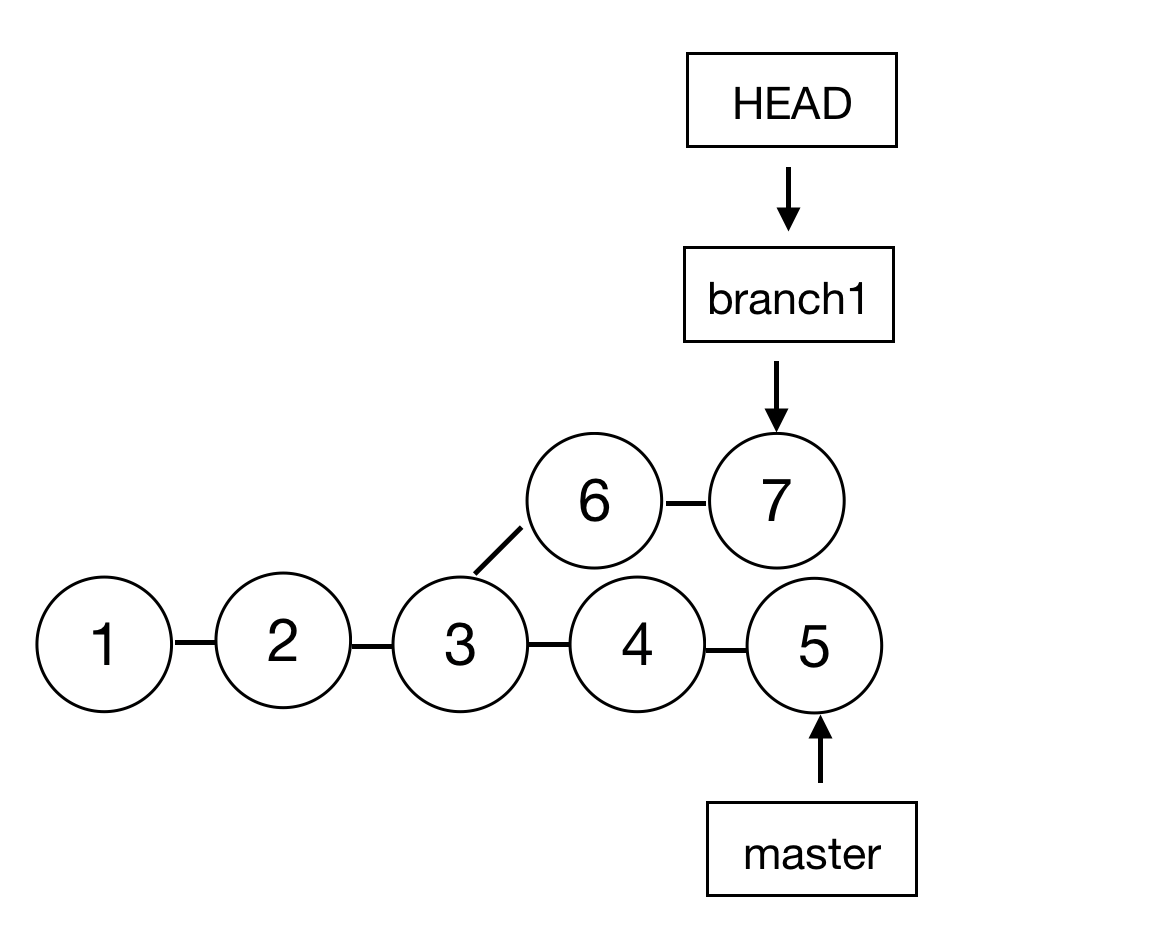
此时切换到开发完成的 branch1 分支下,执行 rebase 然后再在 master 下执行 merge 后的效果:
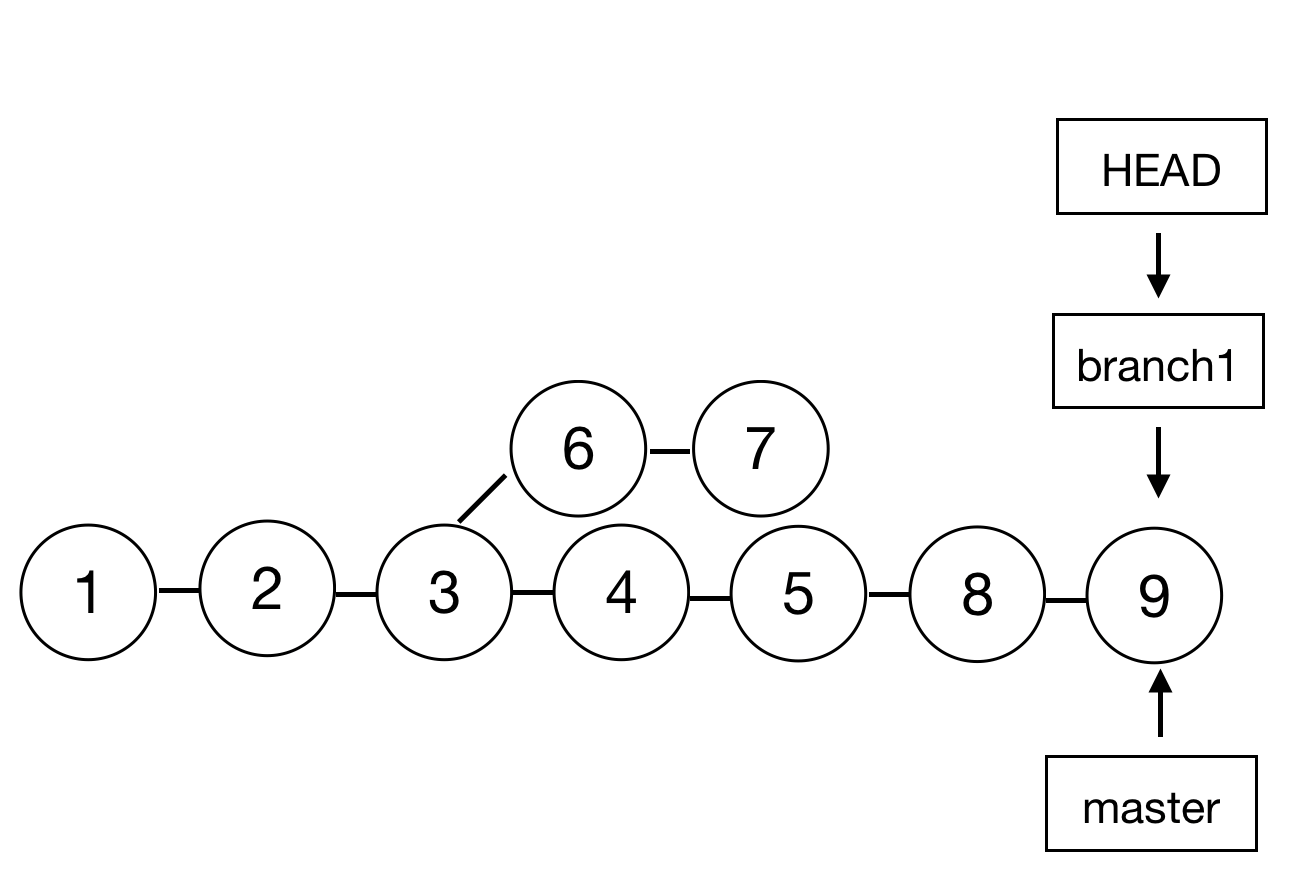
branch1 分支的提交67的基础点会被移动到 master 上,也就是5上。然后将 HEAD 移动到 master 引用上执行 merge ,就将 master 引用又移到了最新的 commit 上。
这两者用法都可以, merge 简单好理解一些,因此大部分人都是在用 merge 。但是无脑的 merge 导致的问题就是提交记录中会出现很多分叉路线,比较混乱难以管理,因此我了不出现分叉,最好用 rebase 来替代 merge 。
对了, merge 有一种特殊情况,就是如果 merge 执行时的目标分支和当前分支并没有分叉,也就是他们其实是在一条分支上,此时有两种情况:如果当前 HEAD 指向的引用领先于目标分支,那么这时的 merge 是一个空操作。而如果是落后于目标分支,那就是一个被称为“快速前移(fast-forward)”的操作,将当前 HEAD 指向往前移动到目标引用处。
同步仓库:pull 和 push
在本地仓库开发完成并向远程仓库同步时,要使用 push 。 笼统的说, push 就是拿本地仓库去覆盖掉远程仓库。当然如果有冲突的话,这一请求会被拒绝掉。实际上, push 命令所做的是:将当前分支,也就是 HEAD 所指向的分支,提交到远程仓库,同时将这一分支上的所有提交也一并提交到远程仓库去。 HEAD 指向 master 这样远程仓库已经存在的分支,那就相当于是更新了远程仓库的分支的提交记录。 而如果指向了其他远程仓库不存在的分支,比如新的 feature1 ,此时就会更新远程仓库信息,告诉他:现在多了一个分支,这个分支有哪些改动。之后其他成员从远程仓库同步下来之后,也得到了你的新的分支信息。
从远程仓库同步下来的操作是 pull 。不过 pull 其实不是一个命令,他内部其实分为了两步。如果不执行 pull ,也可以分别通过这两个命令来实现 pull 的功能,这两个命令就是 fetch 和 merge 。
第一步, git fetch ,他的作用是更新本地仓库关联的所有远程仓库中,各个分支的一系列提交记录。这里只是获取到,并不会有其他操作。第二步 merge ,则是将当前的本地提交与获取到的远程仓库的提交做一个合并,这就是上面说到的 fast-forward 的典型。一般情况下,直接 pull 更简单省事。但是一旦出现冲突,由于会自动的进行 merge ,自动的合并之后可能会出现很多问题,需要自己一个一个查。而如果先 fetch 之后,再查看一下有哪些更新,此时再手动 merge ,就会好很多。
注意事项
在一个团队中使用Git时,一定要细心,中央仓库在服务器上占用的资源是有限的,稍有不慎将一些无用的大体积文件上传到服务器都会造成很大的问题。我这里总结一些经验:
- 尽量少使用
git add -A - 每次
add和commit前后都要注意检查是否有没必要提交的内容 - 本地
commit时要做好code-review - 提交代码,慎用
push -f - 遇事不决先建个分支,这样不管出什么问题起码不会影响到别人
- 执行
commit时填写的 commit信息 一定要规范 - 分支名很重要,不能乱起
- 不用的、弃用的、开发完的一些分支,该删的删,留到后面管理会比较乱
其他
在工作中使用Git的过程中,可能会对一些其他的地方有新的理解,到时候再在后面更新吧,比如常见的一些命令 cherry-pick 、 rebase 等